
This report from The Brookings Institution’s Artificial Intelligence and Emerging Technology (AIET) Initiative is part of “AI Governance,” a series that identifies key governance and norm issues related to AI and proposes policy remedies to address the complex challenges associated with emerging technologies.
Artificial intelligence (AI) presents an opportunity to transform how we allocate credit and risk, and to create fairer, more inclusive systems. AI’s ability to avoid the traditional credit reporting and scoring system that helps perpetuate existing bias makes it a rare, if not unique, opportunity to alter the status quo. However, AI can easily go in the other direction to exacerbate existing bias, creating cycles that reinforce biased credit allocation while making discrimination in lending even harder to find. Will we unlock the positive, worsen the negative, or maintain the status quo by embracing new technology?
This paper proposes a framework to evaluate the impact of AI in consumer lending. The goal is to incorporate new data and harness AI to expand credit to consumers who need it on better terms than are currently provided. It builds on our existing system’s dual goals of pricing financial services based on the true risk the individual consumer poses while aiming to prevent discrimination (e.g., race, gender, DNA, marital status, etc.). This paper also provides a set of potential trade-offs for policymakers, industry and consumer advocates, technologists, and regulators to debate the tensions inherent in protecting against discrimination in a risk-based pricing system layered on top of a society with centuries of institutional discrimination.
AI is frequently discussed and ill defined. Within the world of finance, AI represents three distinct concepts: big data, machine learning, and artificial intelligence itself. Each of these has recently become feasible with advances in data generation, collection, usage, computing power, and programing. Advances in data generation are staggering: 90% of the world’s data today were generated in the past two years, IBM boldly stated. To set parameters of this discussion, below I briefly define each key term with respect to lending.
“Big data” fosters the inclusion of new and large-scale information not generally present in existing financial models. In consumer credit, for example, new information beyond the typical credit-reporting/credit-scoring model is often referred to by the most common credit-scoring system, FICO. This can include data points, such as payment of rent and utility bills, and personal habits, such as whether you shop at Target or Whole Foods and own a Mac or a PC, and social media data.
Related Content

2020
2019
“Machine learning” (ML) occurs when computers optimize data (standard and/or big data) based on relationships they find without the traditional, more prescriptive algorithm. ML can determine new relationships that a person would never think to test: Does the type of yogurt you eat correlate with your likelihood of paying back a loan? Whether these relationships have casual properties or are only proxies for other correlated factors are critical questions in determining the legality and ethics of using ML. However, they are not relevant to the machine in solving the equation.
What constitutes true AI is still being debated, but for purposes of understanding its impact on the allocation of credit and risk, let’s use the term AI to mean the inclusion of big data, machine learning, and the next step when ML becomes AI. One bank executive helpfully defined AI by contrasting it with the status quo: “There’s a significant difference between AI, which to me denotes machine learning and machines moving forward on their own, versus auto-decisioning, which is using data within the context of a managed decision algorithm.”
Current rules
America’s current legal and regulatory structure to protect against discrimination and enforce fair lending is not well equipped to handle AI. The foundation is a set of laws from the 1960s and 1970s (Equal Credit Opportunity Act of 1974, Truth in Lending Act of 1968, Fair Housing Act of 1968, etc.) that were based on a time with almost the exact opposite problems we face today: not enough sources of standardized information to base decisions and too little credit being made available. Those conditions allowed rampant discrimination by loan officers who could simply deny people because they “didn’t look credit worthy.”
Today, we face an overabundance of poor-quality credit (high interest rates, fees, abusive debt traps) and concerns over the usage of too many sources of data that can hide as proxies for illegal discrimination. The law makes it illegal to use gender to determine credit eligibility or pricing, but countless proxies for gender exist from the type of deodorant you buy to the movies you watch.
“America’s current legal and regulatory structure to protect against discrimination and enforce fair lending is not well equipped to handle AI.”
The key concept used to police discrimination is that of disparate impact. For a deep dive into how disparate impact works with AI, you can read my previous work on this topic. For this article, it is important to know that disparate impact is defined by the Consumer Financial Protection Bureau as when: “A creditor employs facially neutral policies or practices that have an adverse effect or impact on a member of a protected class unless it meets a legitimate business need that cannot reasonably be achieved by means that are less disparate in their impact.”
The second half of the definition provides lenders the ability to use metrics that may have correlations with protected class elements so long as it meets a legitimate business need, and there are no other ways to meet that interest that have less disparate impact. A set of existing metrics, including income, credit scores (FICO), and data used by the credit reporting bureaus, has been deemed acceptable despite having substantial correlation with race, gender, and other protected classes.
For example, consider how deeply correlated existing FICO credit scores are with race. To start, it is telling how little data is made publicly available on how these scores vary by race. The credit bureau Experian is eager to publicize one of its versions of FICO scores by people’s age, income, and even what state or city they live in, but not by race. However, federal law requires lenders to collect data on race for home mortgage applications, so we do have access to some data. As shown in the figure below, the differences are stark.
Among people trying to buy a home, generally a wealthier and older subset of Americans, white homebuyers have an average credit score 57 points higher than Black homebuyers and 33 points higher than Hispanic homebuyers. The distribution of credit scores is also sharply unequal: More than 1 in 5 Black individuals have FICOs below 620, as do 1 in 9 among the Hispanic community, while the same is true for only 1 out of every 19 white people. Higher credit scores allow borrowers to access different types of loans and at lower interest rates. One suspects the gaps are even broader beyond those trying to buy a home.
If FICO were invented today, would it satisfy a disparate impact test? The conclusion of Rice and Swesnik in their law review article was clear: “Our current credit-scoring systems have a disparate impact on people and communities of color.” The question is mute because not only is FICO grandfathered, but it has also become one of the most important factors used by the financial ecosystem. I have described FICO as the out of tune oboe to which the rest of the financial orchestra tunes.
New data and algorithms are not grandfathered and are subject to the disparate impact test. The result is a double standard whereby new technology is often held to a higher standard to prevent bias than existing methods. This has the effect of tilting the field against new data and methodologies, reinforcing the existing system.
“Explainability” is another core tenant of our existing fair lending system that may work against AI adoption. Lenders are required to tell consumers why they were denied. Explaining the rationale provides a paper trail to hold lenders accountable should they be engaging in discrimination. It also provides the consumer with information to allow them to correct their behavior and improve their chances for credit. However, an AI’s method to make decisions may lack “explainability.” As Federal Reserve Governor Lael Brainard described the problem: “Depending on what algorithms are used, it is possible that no one, including the algorithm’s creators, can easily explain why the model generated the results that it did.” To move forward and unlock AI’s potential, we need a new conceptual framework.
A new framework
To start, imagine a trade-off between accuracy (represented on the y-axis) and bias (represented on the x-axis). The first key insight is that the current system exists at the intersection of the axes we are trading off: the graph’s origin. Any potential change needs to be considered against the status-quo—not an ideal world of no bias nor complete accuracy. This forces policymakers to consider whether the adoption of a new system that contains bias, but less than that in the current system, is an advance. It may be difficult to embrace an inherently biased framework, but it is important to acknowledge that the status quo is already highly biased. Thus, rejecting new technology because it contains some level of bias does not mean we are protecting the system against bias. To the contrary, it may mean that we are allowing a more biased system to perpetuate.
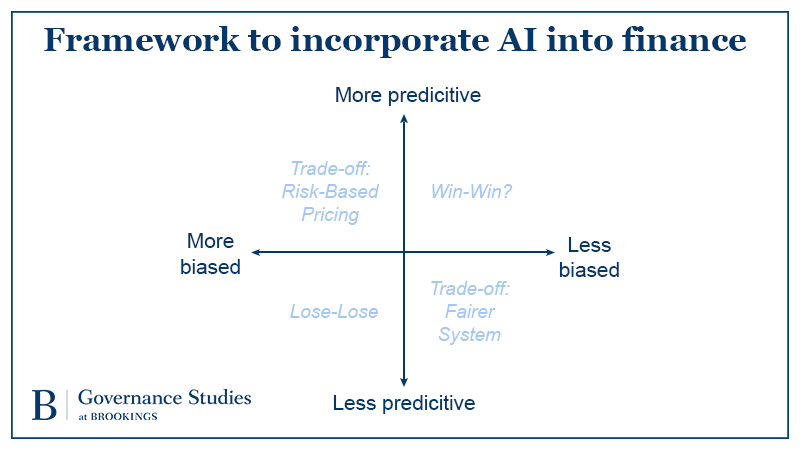
Biased innovation
As shown in the figure above, the bottom left corner (quadrant III) is one where AI results in a system that is more discriminatory and less predictive. Regulation and commercial incentives should work together against this outcome. It may be difficult to imagine incorporating new technology that reduces accuracy, but it is not inconceivable, particularly given the incentives in industry to prioritize decision-making and loan generation speed over actual loan performance (as in the subprime mortgage crisis). Another potential occurrence of policy moving in this direction is the introduction of inaccurate data that may confuse an AI into thinking it has increased accuracy when it has not. The existing credit reporting system is rife with errors: 1 out of every 5 people may have material error on their credit report. New errors occur frequently—consider the recent mistake by one student loan servicer that incorrectly reported 4.8 million Americans as being late on paying their student loans when in fact in the government had suspended payments as part of COVID-19 relief.
The data used in the real world are not as pure as those model testing. Market incentives alone are not enough to produce perfect accuracy; they can even promote inaccuracy given the cost of correcting data and demand for speed and quantity. As one study from the Federal Reserve Bank of St. Louis found, “Credit score has not acted as a predictor of either true risk of default of subprime mortgage loans or of the subprime mortgage crisis.” Whatever the cause, regulators, industry, and consumer advocates ought to be aligned against the adoption of AI that moves in this direction.
A win-win or toleration of discrimination?
The top right (quadrant I) represents incorporation of AI that increases accuracy and reduces bias. At first glance, this should be a win-win. Industry allocates credit in a more accurate manner, increasing efficiency. Consumers enjoy increased credit availability on more accurate terms and with less bias than the existing status quo. This optimistic scenario is quite possible given that a significant source of existing bias in lending stems from the information used. As the Bank Policy Institute pointed out in its in discussion draft of the promises of AI: “This increased accuracy will benefit borrowers who currently face obstacles obtaining low-cost bank credit under conventional underwriting approaches.”
One prominent example of a win-win system is the use of cash-flow underwriting. This new form of underwriting uses an applicant’s actual bank balance over some time frame (often one year) as opposed to current FICO based model which relies heavily on seeing whether a person had credit in the past and if so, whether they were ever in delinquency or default. Preliminary analysis by FinReg Labs shows this underwriting system outperforms traditional FICO on its own, and when combined with FICO is even more predictive.
Cash-flow analysis does have some level of bias as income and wealth are correlated with race, gender, and other protected classes. However, because income and wealth are acceptable existing factors, the current fair-lending system should have little problem allowing a smarter use of that information. Ironically, this new technology meets the test because it uses data that is already grandfathered.
That is not the case for other AI advancements. New AI may increase credit access on more affordable terms than what the current system provides and still not be allowable. Just because AI has produced a system that is less discriminatory does not mean it passes fair lending rules. There is no legal standard that allows for illegal discrimination in lending because it is less biased than prior discriminatory practices. As a 2016 Treasury Department study concluded, “Data-driven algorithms may expedite credit assessments and reduce costs, they also carry the risk of disparate impact in credit outcomes and the potential for fair lending violations.”
For example, consider an AI that is able, with a good degree of accuracy, to detect a decline in a person’s health, say through spending patterns (doctor’s co-pays), internet searches (cancer treatment), and joining new Facebook groups (living with cancer). Medical problems are a strong indicator of future financial distress. Do we want a society where if you get sick, or if a computer algorithm thinks you are ill, that your terms of credit decrease? That may be a less biased system than we currently have, and not one that policymakers and the public would support. Of all sudden what seems like a win-win may not actually be one that is so desirable.
Trade-offs: More accuracy but less fairness
AI that increases accuracy but introduces more bias gets a lot of attention, deservedly so. This scenario represented in the top left (quadrant II) of this framework can range from the introduction of data that are clear proxies for protected classes (watch Lifetime or BET on TV) to information or techniques that, on a first glance, do not seem biased but actually are. There are strong reasons to believe that AI will naturally find proxies for race, given that there are large income and wealth gaps between races. As Daniel Schwarcz put it in his article on AI and proxy discrimination: “Unintentional proxy discrimination by AIs is virtually inevitable whenever the law seeks to prohibit discrimination on the basis of traits containing predictive information that cannot be captured more directly within the model by non-suspect data.”
“Proxy discrimination by AI is even more concerning because the machines are likely to uncover proxies that people had not previously considered.”
Proxy discrimination by AI is even more concerning because the machines are likely to uncover proxies that people had not previously considered. Think about the potential to use whether or not a person uses a Mac or PC, a factor that is both correlated to race and whether people pay back loans, even controlling for race.
Duke Professor Manju Puri and co-authors were able to build a model using non-standard data that found substantial predictive power in whether a loan was repaid through whether that person’s email address contained their name. Initially, that may seem like a non-discriminatory variable within a person’s control. However, economists Marianne Bertrand and Sendhil Mullainathan have shown African Americans with names heavily associated with their race face substantial discrimination compared to using race-blind identification. Hence, it is quite possible that there is a disparate impact in using what seems like an innocuous variable such as whether your name is part of your email address.
The question for policymakers is how much to prioritize accuracy at a cost of bias against protected classes. As a matter of principle, I would argue that our starting point is a heavily biased system, and we should not tolerate the introduction of increased bias. There is a slippery slope argument of whether an AI produced substantial increases in accuracy with the introduction of only slightly more bias. Afterall, our current system does a surprisingly poor job of allocating many basic credits and tolerates a substantially large amount of bias.
Industry is likely to advocate for inclusion of this type of AI while consumer advocates are likely to oppose its introduction. Current law is inconsistent in its application. Certain groups of people are afforded strong anti-discrimination protection against certain financial products. But again, this varies across financial product. Take gender for example. It is blatantly illegal under fair lending laws to use gender or any proxy for gender in allocating credit. However, gender is a permitted use for price difference for auto insurance in most states. In fact, for brand new drivers, gender may be the single biggest factor used in determining price absent any driving record. America lacks a uniform set of rules on what constitutes discrimination and what types of attributes cannot be discriminated against. Lack of uniformity is compounded by the division of responsibility between federal and state governments and, within government, between the regulatory and judicial system for detecting and punishing crime.
Trade-offs: Less accuracy but more fairness
The final set of trade-offs involve increases in fairness but reductions in accuracy (quadrant IV in the bottom right). An example includes an AI with the ability to use information about a person’s human genome to determine their risk of cancer. This type of genetic profiling would improve accuracy in pricing types of insurance but violates norms of fairness. In this instance, policymakers decided that the use of that information is not acceptable and have made it illegal. Returning to the role of gender, some states have restricted the use of gender in car insurance. California most recently joined the list of states no longer allowing gender, which means that pricing will be more fair but possibly less accurate.
Industry pressures would tend to fight against these types of restrictions and press for greater accuracy. Societal norms of fairness may demand trade-offs that diminish accuracy to protect against bias. These trade-offs are best handled by policymakers before the widespread introduction of this information such as the case with genetic data. Restricting the use of this information, however, does not make the problem go away. To the contrary, AI’s ability to uncover hidden proxies for that data may exacerbate problems where society attempts to restrict data usage on the grounds of equity concerns. Problems that appear solved by prohibitions then simply migrate into the algorithmic world where they reappear.
The underlying takeaway for this quadrant is one in which social movements that expand protection and reduce discrimination are likely to become more difficult as AIs find workarounds. As long as there are substantial differences in observed outcomes, machines will uncover differing outcomes using new sets of variables that may contain new information or may simply be statistically effective proxies for protected classes.
Final takeaways
The status quo is not something society should uphold as nirvana. Our current financial system suffers not only from centuries of bias, but also from systems that are themselves not nearly as predictive as often claimed. The data explosion coupled with the significant growth in ML and AI offers tremendous opportunity to rectify substantial problems in the current system. Existing anti-discrimination frameworks are ill-suited to this opportunity. Refusing to hold new technology to a higher standard than the status quo results in an unstated deference to the already-biased current system. However, simply opening the flood gates under the rules of “can you do better than today” opens up a Pandora’s box of new problems.
“The status quo is not something society should uphold as nirvana. Our current financial system suffers not only from centuries of bias, but also from systems that are themselves not nearly as predictive as often claimed.”
America’s fractured regulatory system, with differing roles and responsibilities across financial products and levels of government, only serves to make difficult problems even harder. With lacking uniform rules and coherent frameworks, technological adoption will likely be slower among existing entities setting up even greater opportunities for new entrants. A broader conversation regarding how much bias we are willing to tolerate for the sake of improvement over the status quo would benefit all parties. That requires the creation of more political space for sides to engage in a difficult and honest conversation. The current political moment in time is ill-suited for that conversation, but I suspect that AI advancements will not be willing to wait until America is more ready to confront these problems.
The Brookings Institution is a nonprofit organization devoted to independent research and policy solutions. Its mission is to conduct high-quality, independent research and, based on that research, to provide innovative, practical recommendations for policymakers and the public. The conclusions and recommendations of any Brookings publication are solely those of its author(s), and do not reflect the views of the Institution, its management, or its other scholars.
Microsoft provides support to The Brookings Institution’s Artificial Intelligence and Emerging Technology (AIET) Initiative, and Apple, Facebook, and IBM provide general, unrestricted support to the Institution. The findings, interpretations, and conclusions in this report are not influenced by any donation. Brookings recognizes that the value it provides is in its absolute commitment to quality, independence, and impact. Activities supported by its donors reflect this commitment.
Author



